4 数据流分析-基础
4.1 重新审视迭代算法
算法4.1 可能性(May Analysis)正向(Forward Analysis)数据流分析的迭代(Iterative)算法
其他类型的数据流分析也有类似的迭代算法,我们后续以算法4.1为例进行理论的分析和讲解。迭代算法是一个具有通用性的数据流分析算法,能够提供一种数据流分析的解决方案(解决方案的含义见结论3.2)。
下面我们从另一个视角来审视一下迭代算法。
(OUT[n1],OUT[n2],...,OUT[nk])∈V×V×...×V=Vk 于是,算法的过程可以表示为:
| 初始化 | (⊥,⊥,...,⊥)=X0 |
|---|
| 第1次迭代 | (v11,v21,...,vk1)=X1=F(X0) |
| 第2次迭代 | (v12,v22,...,vk2)=X2=F(X1) |
| ...... | ...... |
| 第i次迭代 | (v1i,v2i,...,vki)=Xi=F(Xi−1) |
| 第i+1次迭代 | (v1i,v2i,...,vki)=Xi+1=F(Xi)=Xi |
其中, vij 表示第i个结点第j次迭代后的数据流值。
算法终止的时候,我们发现 Xi+1=F(Xi)=Xi ,因此 Xi 是函数 F 的一个不动点(Fixed Point),故而我们称算法到达了一个不动点。
不过这时我们会有一些疑问:
算法保证能够终止吗?也就是说不动点一定存在吗?或者说数据流分析是否总会有一个解决方案?
如果是的话,不动点是只有一个吗?不止一个的话,我们算法终止的不动点是最好的那个吗?
算法什么时候会到达不动点?或者说我们什么时候能够得到一个解决方案?
为了回答上面这些问题,我们需要一些离散数学的内容作铺垫。
4.2 唤醒一些记忆深处的数学
4.2.1 偏序
定义4.1
我们定义偏序集(Poset)为 (P,⪯) ,其中 ⪯ 为一个二元关系(Binary Relation),这个二元关系在 P 上定义了 偏序(Partial Ordering) 关系,并且 ⪯ 具有如下性质:
自反性(Reflexivity) : ∀x∈P,x⪯x ;
反对称性(Antisymmetry) : ∀x,y∈P,x⪯y∧y⪯x⇒x=y ;
传递性(Transitivity) : ∀x,y,z∈P,x⪯y∧y⪯z⇒x⪯z 。
例如 (Z,≤) 是偏序集, (2S,⊆) 也是偏序集。并且,偏序意味着集合中可能存在某两个元素,它们之间是不可比(Incomparable)的。任意两个元素都可比的偏序集称为全序集。
定义4.2
考虑偏序集 (P,⪯) 及其子集 S⊆P ,我们称 u∈P 是 S 的一个 上界(Upper Bound) ,如果 ∀x∈S,x⪯u 。类似的,我们称 l∈P 是 S 的一个 下界(Lower Bound) ,如果 ∀x∈S,l⪯x 。
定义4.3
考虑偏序集 (P,⪯) 及其子集 S⊆P ,定义 S 的 最小上界(Least Upper Bound, LUB) 为 ∨S ,使得对于 S 的任意一个上界 u ,有 ∨S⪯u 。
类似的,定义 S 的 最大下界(Greatest Lower Bound, GLB) 为 ∧S ,使得对于 S 的任意一个下界 l ,有 l⪯∧S 。
通常,如果 S 只包含两个元素 a 和 b ,即 S={a,b} ,则 ∨S 可写作 a∨b ,称为 a 和 b 的 联合(Join) ; ∧S 可写作 a∧b ,称为 a 和 b 的 交汇(Meet) 。
并不是每一个偏序集都有最小上界或者最大下界,比如说 (Z,≤) ,子集 Z+ 就没有最小上界。
定理4.1
如果一个偏序集存在最小上界,则这个偏序集最小上界是唯一的;如果一个偏序集存在最大下界,则这个偏序集的最大下界也是唯一的。
证明:反证法。假设偏序集 (P,⪯) 存在两个不同的最小上界 g1,g2∈P ,根据最小上界的定义有 g1⪯g2∧g2⪯g1 ,有偏序关系的反对称性可知 g1=g2 ,这与两个不同的最小上界矛盾,因此这个偏序集的最小上界是唯一的。同理,一个偏序集的最大下界如果存在,也是唯一的。
4.2.2 格
定义4.4
考虑偏序集 (P,⪯) ,如果 ∀a,b∈P , a∨b 和 a∧b 都存在,则我们称 (P,⪯) 为 格(Lattice) 。
简单理解,格是每对元素都存在最小上界和最大下界的偏序集。
比如说 (Z,≤) 是格,其中 ∨=max,∧=min ; (2S,⊆) 也是格,其中 ∨=∪,∧=∩ 。
定义4.5
考虑偏序集 (P,⪯) ,
如果 ∀a,b∈P , a∨b 存在,则我们称 (P,⪯) 为 联合半格(Joint Semilattice) ;
如果 ∀a,b∈P , a∧b 存在,则我们称 (P,⪯) 为 交汇半格(Meet Semilattice) ;
联合半格和交汇半格统称为 半格(Semilattice) 。
定义4.6
考虑偏序集 (P,⪯) ,如果 ∀S⊆P , ∨S 和 ∧S 都存在,则我们称 (P,⪯) 为 全格(Complete Lattice) 。
简单理解,全格的所有子集都有最小上界和最大下界。由于 (Z,≤) ,子集 Z+ 没有最小上界,因此它不是全格;与之不同的, (2S,⊆) 就是一个全格。
定理4.2
每一个全格 (P,⪯) 都有一个 序最大(Greatest) 的元素 ⊤=∨P 称作 顶部(Top) ,和一个 序最小(Least) 的元素 ⊥=∧P 称作 底部(Bottom) 。
定理4.3
每一个有限格(Finite Lattice) (P,⪯) ( P 是有限集)都是一个全格。
定义4.7
考虑偏序集 L1=(P1,⪯1),L2=(P2,⪯2),...,Ln=(Pn,⪯n) ,其中 Li=(Pi,⪯i),i=1,2,...,n 的LUB运算为 ∨i ,GLB运算为 ∧i ,定义 积格(Product ) 为 Ln=(P,⪯) ,满足:
- P=P1×P2×...×Pn
- (x1,x2,...,xn)⪯(y1,y2,...,yn)⇔(x1⪯y1)∧(x2⪯y2)∧...∧(xn⪯yn)
- (x1,x2,...,xn)∧(y1,y2,...,yn)=(x1∧y1,x2∧y2,...,xn∧yn)
- (x1,x2,...,xn)∨(y1,y2,...,yn)=(x1∨y1,x2∨y2,...,xn∨yn)
4.2.3 不动点
定义4.8
我们称一个函数 fL→L ( L 是格)是 单调的(Monotonic) ,具有 单调性(Monotonicity) ,如果 ∀x,y∈L,x⪯y⇒f(x)⪯f(y) 。
其实,格和格所在的那个集合我们一般是不严格区分的,也就是说,L既可以表示格,也可以表示定义格的那个集合。
定义4.9
我们称 x 是一个函数 f 的 不动点(Fixed Point) ,如果 f(x)=x 。
定义4.10
我们定义一个 格的高度 h 为从底部到顶部的最长路径。
定理4.6 不动点定理(Fixed-Point Theorem)
考虑一个全格 (L,⪯) ,如果 fL→L 是单调的且 L 是有限集,那么 序最小的不动点(Least Fixed Point) 可以通过如下的迭代序列找到:
f(⊥),f(f(⊥)),...,fh+1(⊥) 序最大的不动点(Greatest Fixed Point) 可以通过如下的迭代序列找到:
f(⊤),f(f(⊤)),...,fh+1(⊤) 其中, h 是 L 的高度。
下面证明这个定理。具有代表性地,这里只证一下序最小的不动点,序最大的不动点也是类似的。
证明:由定理4.2,有 ⊥⪯f(⊥) ,而 f 是单调的,则 f(⊥)⪯f(f(⊥))=f2(⊥) (定义4.9)。
多次应用 f ,结合 L 是有限集,考虑 L 的高度 h 我们可以得到一个 h+2 个元素的递增序列:
⊥⪯f(⊥)⪯f2(⊥)⪯...⪯fh+1(⊥) 根据鸽笼原理,存在 0≤k<j≤h+1 ,使得 fk(⊥)=fj(⊥) ,其中,记 f0(⊥)=⊥ 。
又因为 fk(⊥)⪯fk+1(⊥)⪯...⪯fj(⊥) ,由偏序关系的反对称性有 fk(⊥)=fk+1(⊥) 。
于是,我们找到了一个不动点 x0=fk(⊥) ,使得 f(x0)=x0 。不动点的存在性证毕。
下面证明找到的这个不动点是最小不动点。
反证法。假设我们有一个序更小的不动点 x1≺x0 (即 x1⪯x0∧x1=x0 ),使得 f(x1)=x1 。
由定理4.2,我们有 ⊥⪯x1 ,而 f 是单调的,则 f(⊥)⪯f(x1)=x1 。
多次应用 f ,不难有 x0=fk(⊥)⪯x1 ,这与 x1≺x0 是矛盾的。
因此不存在序更小的不动点,不动点的序最小性证毕。
综上,不动点定理的第一部分是正确的,第二部分类似可证。
到此为止,我们得到了一个格上的单调函数一定能够对端点元素( ⊤ 或 ⊥ )迭代出不动点的性质。
不过我们还不能因此说明我们的迭代算法也有这样的性质,除非我们之后可以将迭代算法和不动点定理关联起来。
定理4.7
交汇 ∧ / 联合 ∨ 操作是单调的。
证明:
∀x,y,z∈L ,若 x⪯y ,由于 x∧z⪯x⪯y , x∧z⪯z ,于是有 x∧z⪯y∧z ,从而 ∧ 是单调的。
∀x,y,z∈L ,若x⪯y,由于 x⪯y⪯y∨z , z⪯y∨z ,于是有 x∨z⪯y∨z ,从而 ∨ 也是单调的。
4.2.4 分配性
定理4.8
定义在格 (L,⪯) 上的单调函数 f(x) 满足: f(x)∨f(y)⪯f(x∨y) , f(x∧y)⪯f(x)∧f(y) 。
证明:
由 x⪯x∨y 且 f(x) 单调,有 f(x)⪯f(x∨y) ,同理 f(y)⪯f(x∨y) ,于是 f(x)∨f(y)⪯f(x∨y) 。
由 x∧y⪯x 且 f(x) 单调,有 f(x∧y)⪯f(x) ,同理 f(x∧y)⪯f(y) ,于是 f(x∧y)⪯f(x)∧f(y) 。
定义4.11
我们称定义在格 (L,⪯)上的函数 f(x) 满足分配性(Distributive),如果 f(x∨y)=f(x)∨f(y) , f(x∧y)=f(x)∧f(y) 。
4.3 基于格的数据流分析框架
定义4.12
一个数据流分析框架(Data Flow Analysis Framework) (D,L,F) 由以下3个部分组成:
D (Direction):数据流的方向——正向或者逆向;
L (Lattice):一个包含值集 V 的域(即 V 的幂集)的格以及一个交汇操作符(Meet Operator)或者联合操作符(Joint Operator);
F (Function Family):一个从 V 到 V 的转移函数族(Transfer Function Family)。
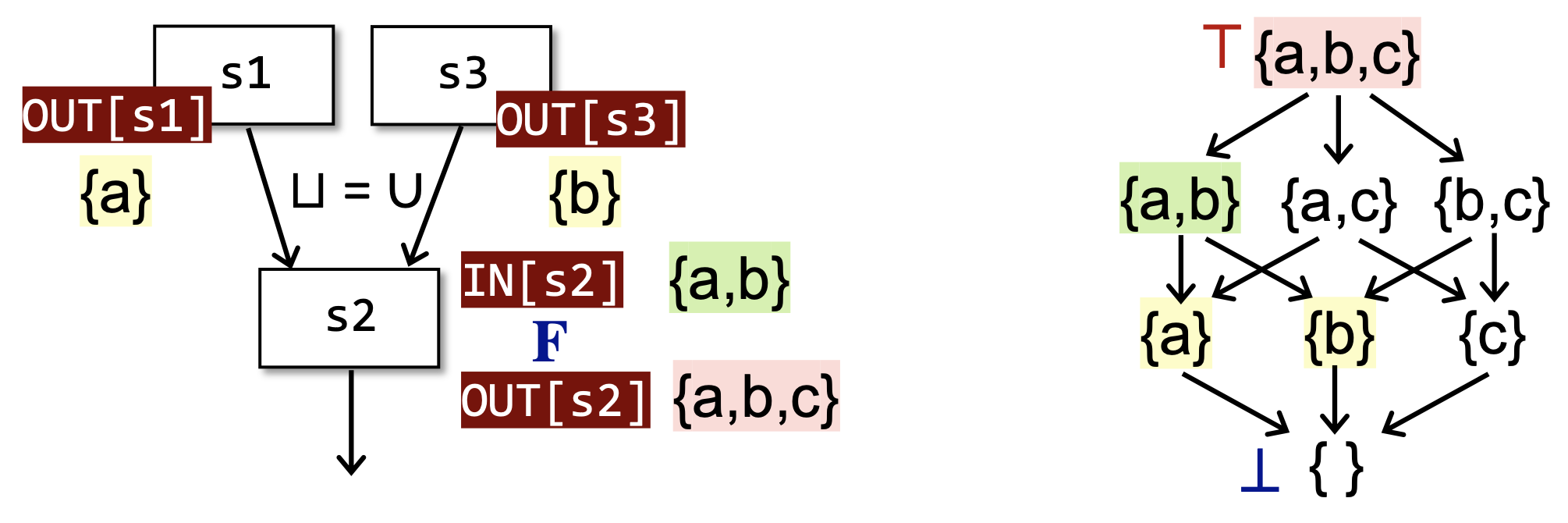
对于每一个结点来说,数据流分析可以被视为在某个格的值上面迭代地应用转移函数和交汇/联合操作的过程。因为定义域是值集 V 的幂集,而幂集本身就是一个天然的全格,记为 (L,⊆) 。
那么,对于整个CFG来说,数据流分析可以被视为在所有结点的格的积格上面迭代地应用转移函数和交汇/联合操作的过程,假设有 k 个结点,则迭代算法的每一次迭代可视为 FLk→Lk (结合4.1来看)。其中 Lk 是一个全格(见定理4.5)。所以,根据定理4.6,我们只需要证明 F 是单调的,就可以回答4.1最后三个问题:迭代算法一定会达到不动点,并且达到的是序最小的不动点(对于正向、可能性分析,逆向、必然性分析也是类似的),且可以在 O(kh) 内达到,其中 h 是定义域格的高度。
F 有两个部分组成,一个部分是状态转移方程 fL→L ,从定理3.4后面的证明中我们可以发现,定义可达性分析的状态转移方程是单调的,类似的,变量活性分析和可用表达式分析的状态转移方程都是单调的。在我们进行其他分析的时候,我们设计状态转移方程时,需要保证其单调性。也就是说,一个设计糟糕的状态转移方程可能是不单调的,从而导致我们的迭代算法无法终止,或者无法求出符合预期的结果。
其实 gen/kill 形式的状态转移方程一般都是单调的,因为它的输出状态不会收缩。
另一个部分是由控制流产生的交汇/联合操作函数 fL×L→L ,从定理4.7我们不难看出,它也是单调的,从而 F 是单调的。
因此满足不动点定理的条件,我们的迭代算法一定会达到一个最好(可能性分析则是序最小,必然性分析则是序最大)的不动点。并且,从不动点定理的证明中我们可以发现,迭代次数最多为格的高度,我们不妨记定义域格的高度为 h ,则每次迭代的最坏情况是 k 个格中只有一个格变化了一次,并且直到 ⊤ 才找到不动点,在这种最坏情况下,迭代的次数为 k⋅h+1 ,最后一次用于确认所有的数据流值都不会发生变化了。于是,我们便可以分析出算法的复杂度了。
定理4.9
假设集合操作是常数项时间,则数据流分析的迭代算法的时间复杂度为 O(kh) ,其中 k 为 CFG 的结点个数, h 为定义域格的高度。
位向量实现的集合操作就是常数项时间,哈希表接近常数项时间,红黑树为对数时间。
4.4 格视角下的可能性分析与必然性分析
4.4.1 可能性分析
我们以典型的可能性分析——Reaching Definitions为例。从某个程序点的视角来看,我们初始化的时候是 ⊥ ,即没有任何定义可以到达此处,然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越多的定义能够到达此处,直到算法在一个最小的不动点处停了下来。
首先,初始化的状态是不安全的,因为没有任何定义可达显然是一个最不正确的结论。其次, ⊤ 状态是最安全的,所有的定义都“可能”到达此处,但这是一个没有用的平凡的结论,因为它并不能帮到我们什么,且我们啥也不干都知道这个结论。
我们假设这个程序点处真实可达的定义集合为 Truth ,那么 包含 Truth 且越接近 Truth 的答案才是最有价值的。因此,在包含 Truth 的前提下最小的不动点是最好的。
至于最小的不动点为什么会包含 Truth ,这是由我们设计的转移方程和控制流约束函数所决定的,需要具体的问题具体分析。言下之意,如果我们设计的状态转移方程和控制流约束函数不合理,最小不动点可能会是不安全的,也就是算法可能会出错。
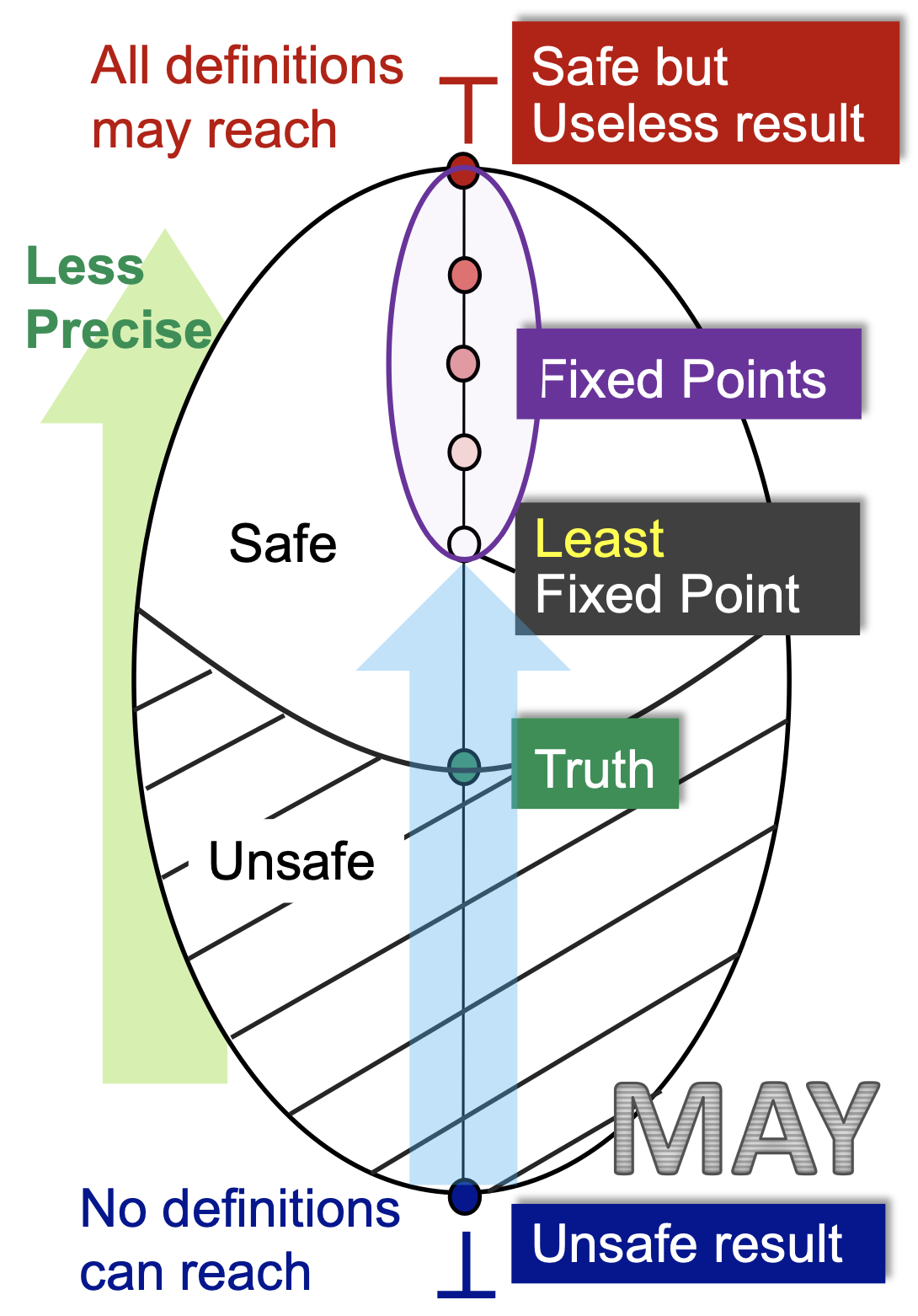
这里还需要强调一下的是,因为定义域是值集的幂集,所以格上的每个元素都是值集的一个子集。对于定义可达性问题来说,值集是整个程序中所有的定义组成的集合 D={d1,d2,...,dn} ,而对应数据流分析的定义域其实是 V=2D 。所以Truth和Least Fixed Point都是一个集合。在这个格上的序大小关系其实就是集合的包含关系。
从上面可以看出,数据流分析的过程是从不安全到安全(From Unsafe to Safe),然后从准到不准(From Precise to Less Precise)的过程。可能性分析如此,必然性分析也是如此。
4.4.2 必然性分析
我们以典型的必然性分析——Available Expressions为例。从某个程序点的视角来看,我们初始化的时候是 ⊤ ,即所有的表达式都是可用的,然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越少的表达式是可用的,直到算法在一个最大的不动点处停了下来。
首先,初始化的状态是不安全的,因为所有的表达式都可用显然是一个最不正确的结论(如果我们用这个结论来作表达式优化,是最会导致程序错误的)。其次, ⊥ 状态是最安全的,所有的表达式都不可用(也就是我们并不能优化,啥也不用干就行),但这是一个没有用的结论,因为它并不能帮助我们优化表达式,减少计算次数。
我们假设这个程序点处真实可用的表达式集合为 Truth ,那么包含于 Truth (注意,可能性分析里面是包含,必然性分析里面是包含于)且越接近 Truth 的答案才是最有价值的。因为包含于 Truth 说明用这个结果做优化一定不会错,越接近 Truth 那么我能够优化掉的表达式才越多,优化效果越好。因此,在包含于 Truth 的前提下最大的不动点是最好的。
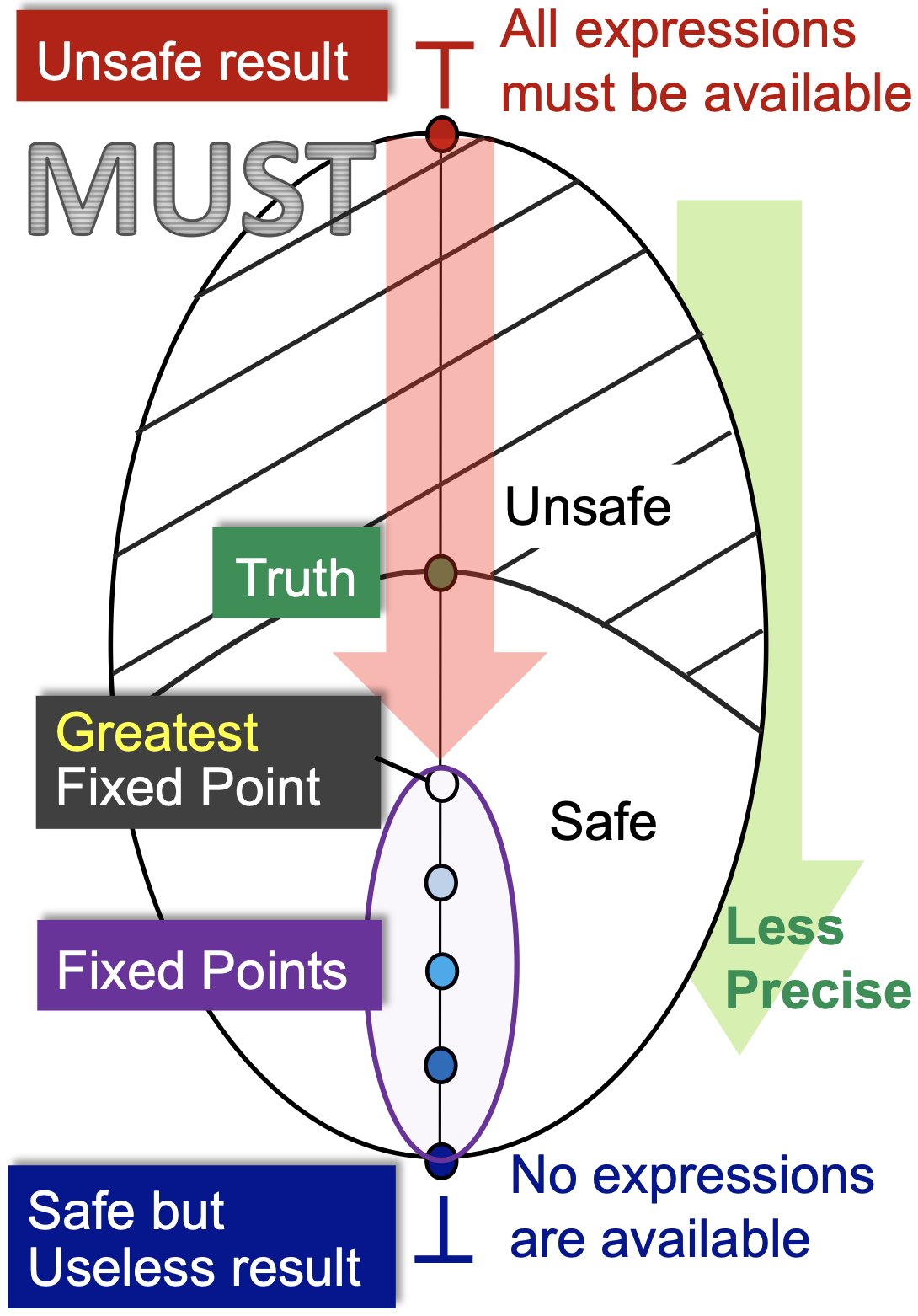
至于最大的不动点为什么会包含于 Truth ,这是由我们设计的状态转移方程和控制流约束函数所决定的,需要具体问题具体分析。言下之意,如果我们设计的状态转移方程和控制流约束函数不合理,最大不动点可能会是不安全的,也就是算法可能会出错。
到这里我们会再一次从新的视角发现,可能性分析和必然性分析的区别就是对于安全近似的判断标准不同,可能性分析的适用的是过近似的原则,言下之意多多益善,油多不坏菜;必然性分析适用的是欠近似原则,言下之意宁可放过,绝不错杀,放过事小,错杀事大。
4.5 算法精度分析
我们通过对比的方式来简要分析一下迭代算法的精度。首先,介绍一种以暴力枚举为基本思想的算法,虽然暴力算法比较慢,但是可以将其作为一个理论工具来衡量一些可行算法(比如说迭代算法)的精度。
4.5.1 全路交汇的解决方案
定义4.13
考虑从程序入口到沿着某条控制流某个程序点si处所经过的所有语句,记为 P=ENTRY→s1→s2→...→si ,称序列 s1s2...si 是到程序点 (si,si+1) (见定义3.4)的一条 路径(Path)。
定理4.10
若路径 s1s2...si 上每个语句的状态转移方程(见定义3.7)为 fsi ,则路径P的状态转移方程为
FP=fsi∘fsi−1∘...∘fs2∘fs1 定义4.14
数据流分析的 全路交汇(Meet-Over-All-Paths) 的解决方案通过如下步骤计算某个程序点 (si,si+1) 处的数据流值,记为 MOP[si] :
考虑从程序入口到 si 处的路径 P 的状态转移方程 FP,所有路径的集合记为 Paths(ENTRY,si) ;
使用联合或者交汇操作来求这些值的最小上界或者最大下界。
形式化表示为:
MOP[si]=∀P∈Paths(ENTRY,si)⋁FP(OUT[ENTRY]) 或
MOP[si]=∀P∈Paths(ENTRY,si)⋀FP(OUT[ENTRY]) 由于CFG中并不是每一条控制流都会被执行的,所以MOP算法并不是完全精确的。并且,由于MOP算法需要考虑所有的路径,因此它也是不现实的。故而,我们并不会实际使用MOP算法,而更多的把MOP当作是用于比较分析其他算法精度的标尺。
4.5.2 MOP与迭代算法的比较
我们通过一个例子来比较一下这两个算法。
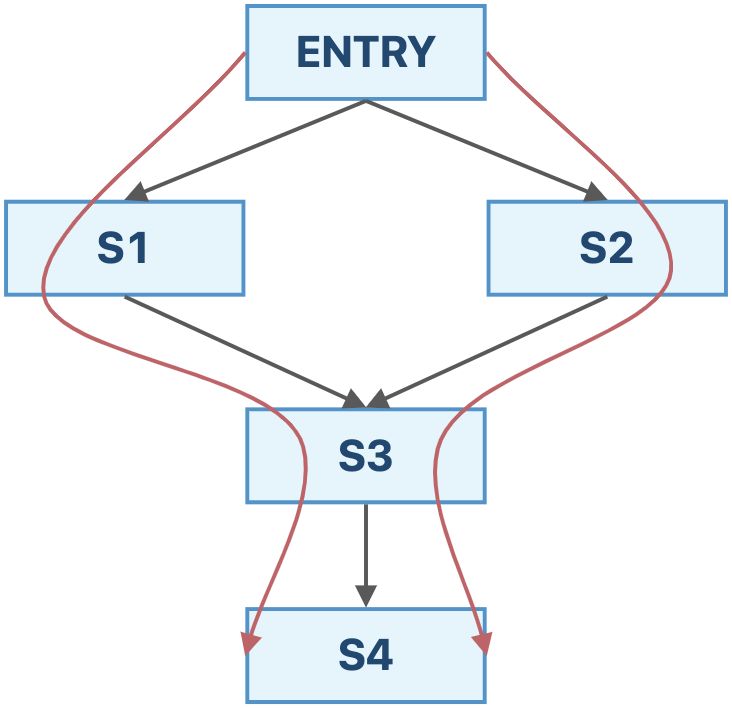
如果采用迭代算法,我们最终得到的结果为:
IN[s4]=fs3(fs1(OUT[ENTRY])∨fs2(OUT[ENTRY])) 如果采用MOP算法,我们最终得到的结果为:
IN[s4]=fs3(fs1(OUT[ENTRY]))∨fs3(fs2(OUT[ENTRY])) 从这个例子中,我们可以发现,迭代算法求的是 F(x∨y) ,而MOP算法求的是 F(x)∨F(y) (如果是交汇操作也是类似的)。
根据定理4.8,有 F(x)∨F(y)⪯F(x∨y) ,结合4.4.1(以May Analysis为例),迭代算法的精度不如MOP。
不过,当 F(x) 满足分配性的时候,迭代算法的精度和MOP是一样的。并且,目前我们学过的3中数据流分析的状态转移方程都是满足分配性的。也就是说,在这些情景下,迭代算法可以达到MOP算法的精度,但是其实现要比MOP简单得多。
其实,对于许多可以通过 gen/kill 的视角解决的问题,它们的状态转移都是满足分配性的。不过也有一些问题的状态转移函数并不满足分配性,比如说4.6。
4.6 常量传播
4.6.1 问题描述
定义4.15
常量传播(Constant Propagation) 问题:考虑程序点 p 处的变量 x ,求解 x 在 p 点处是否保证(Guarantee)是一个常量。
如果我们知道了某些程序点处的某些变量一定是一个常量的话,我们就可以直接优化,将这个变量视为常量,从而减少内存的消耗(可以在编译的时候就完成一部分计算,并且有些常量并不需要分配储存它的内存空间)。
4.6.2 问题分析
数据抽象
我们可以用一个有序对 (x,v) 的集合表示每个程序点处的抽象程序状态,其中 x 是变量名, v 是变量的常数值, v 的取值可能有某个常数, UNDEF (Undefined,未定义的)或 NAC (Not A Constant,不是常量)。
控制流约束
基于此,我们可以定义值之间的交汇操作:
(x,v)∧(x,NAC)=(x,NAC) ,变量和任意常量交汇还是变量,因为我们需要保证是一个常量,采用的是必然性分析的策略;
(x,UNDEF)∧(x,v)=(x,v) ,未初始化的变量并不是我们这个问题的关注点(言下之意出了Undefined的错误,锅由Reaching Definitions背),我们当它不存在即可。
(x,v1)∧(x,v2)={(x,v1),if v1=v2(x,NAC),otherwise ,两个不同的值汇聚到某一点,说明这个变量不是常量,否则,在这个程序点处,我们可以将其视为常量。
状态转移方程
考虑语句 s: x = ... ,定义其状态转移方程为:
F:OUT[s]=gens∪(IN[s]−{(x,_)}) 其中, (x,_) 是一个通配符,表示所有的以 x 作为第一个元素的有序数对。
为了表示方便,我们下面用 val(x) 来表示变量 x 的值(可能是常数,UNDEF或者NAC),定义 gens 如下:
s: x = c; //c is a constant ,则 gens={(x,c)} ;
s: x = y; ,则 gens={(x,val(y))} ;
s: x = y op z; ,则 gens={(x,f(y,z))} ,其中,
f(y,z)=⎩⎪⎪⎨⎪⎪⎧val(y) op val(z)if y and z are constantsNACif y or z isNACUNDEFotherwise 关于上述第二种情况,我们认为 NAC/0 和 NACmod0 的结果为 UNDEF ,当然这对常量优化来说并不重要。
如果 s 不是赋值语句,那么 F:OUT[s]=IN[s] (Identity Function)。
4.6.3 区别
我们前面学的3种数据流分析,其转移方程都满足分配性,而常量传播的转移方程是不满足分配性的,我们可以用一个例子来看。
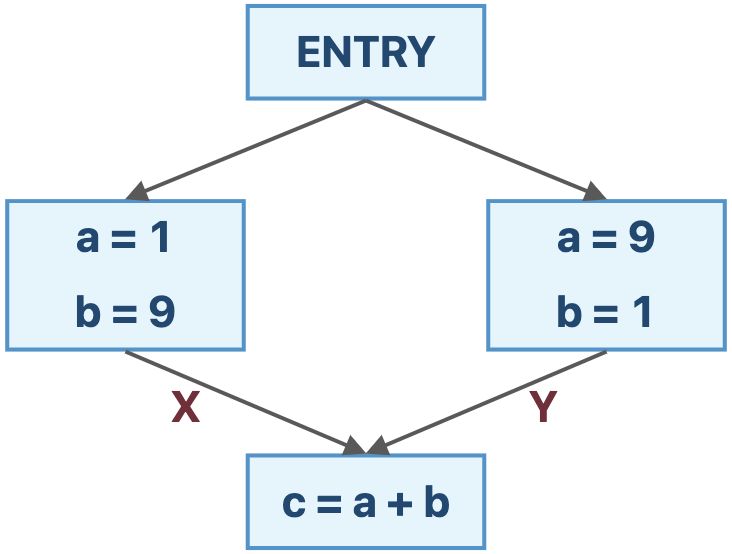
在上图的例子中,
F(X∧Y)={(a,NAC),(b,NAC),(c,NAC)} 而
F(X)∧F(Y)={(a,NAC),(b,NAC),(c,10)} 虽然 F(X∧Y)⪯F(X)∧F(Y) ,与单调性是契合的;但是 F(X∧Y)=F(X)∧F(Y) ,不满足分配性。
因此,迭代算法的精度达不到MOP精度。
4.7 工作表算法
算法4.2 可能性(May Analysis)正向(Forward Analysis)数据流分析的工作表(Worklist)算法
工作表算法是对迭代算法的优化,用一个集合储存下一次遍历会发生变化的基块,这样,已经达到不动点的基块就可以不用重复遍历了。这里需要提一下的是 Worklist 最好采用去重的集合实现,不然的话, Worklist 中可能有重复的基块。
还有一个需要解释一下的地方是,算法的最后一行只将输出状态发生变化的基块的后继,也就是在下一轮当中输入状态会发生变化的基块加入工作表,这是由于只有当输入状态发生变化时,输出状态才会发生变化,因为 genB 和 killB 是提前计算好的,且不会变化的 。
其实这个算法本质上是图的广度优先遍历算法的变体,只是加入了一些剪枝的逻辑,每一轮只遍历可能会发生变化的结点,不发生变化的结点提前从遍历逻辑中去除。
4.8 自检问题
如何从函数的角度来看待数据流分析的迭代算法?
格和全格的定义是什么?
如何理解不动点定理?
怎样使用格来总结可能性分析与必然性分析?
迭代算法提供的解决方案与MOP相比而言精确度如何?
什么是常量传播(Constant Propagation)分析?
数据流分析的工作表算法(Worklist Algorithm)是什么?
